Nach mehr Aufgaben
Wie wir im vorherigen Beitrag diskutiert haben, hat die Speicherverwaltung in einem Betriebssystem häufig noch zwei zusätzliche Aufgaben jenseits der reinen Zuteilung:
- Prozesse sollen davor geschützt werden, dass sie sich gegenseitig in den Speicher schreiben können;
- Es soll mehr Speicher genutzt werden können, als real zur Verfügung steht.
Beides wird in der Regel mit dem gleichen Ansatz realisiert: gestreute Adressierung mit Paging1. Wir wollen zunächst in ɒiʜꟼOS nur die erste Aufgabe erfüllen.
Paging auf dem ARM
Tabellen
Das Paging auf unserem Prozessor2 erfolgt – wenn es den angeschaltet ist – ein- bis -zweistufig. Das Top-Level-Verzeichnis kann den vollständigen adressierbaren Speicherbereich organisieren, das sind bei einer Adressbreite von 32 Bit 4 GiB. In diesem Verzeichnis gibt es 1024 Einträge zu je 4 Byte, so dass das gesamte Verzeichnis 4 kiB groß ist und jeder für Eintrag 1 MiB steht. Ein solcher Eintrag kann verschiedene Dinge enthalten:
- Seitenfehler (page fault): Der Zugriff auf diesen Speicher führt zu einer Ausnahme (abort);
- Section: Ein Speicherbereich von 1 MiB Größe;
- Verweis auf eine Seitentabelle, die ebenfalls einen Speicherbereich von 1 MiB Größe beschreibt, jedoch eine feinere Unterteilung zulässt.
Darüber hinaus gibt noch die sogenannte Supersection: einen Speicherbereich von 16 MiB Größe. Wer jetzt aber glaubt, damit könnte man das Top-Level-Verzeichnis kleiner machen, irrt sich: wenn Supersections genutzt werden, muss jeder entsprechende Eintrag 16 mal im Verzeichnis vorhanden sein. In ɒiʜꟼOS werden wir Supersections nicht nutzen.
Um eine Verwechslung auszuschließen, wird im Folgenden das Top-Level-Verzeichnis als Seitenverzeichnis (page directory) und die Verzeichnisse der zweiten Stufe als Seitentabellen (page tables) bezeichnet. Diese Namen sind häufig im Gebrauch, kommen aber in der ARM-Dokumentation nicht vor: dort wird nut von first level table und second level tables gesprochen.
Ein Seitentabelle ist 1 kiB groß und enthält 256 Einträge. Jeder der Einträge kann wieder von unterschiedlicher Art sein:
- Seitenfehler (hatten wir ja schon)
- große Speicherseite mit 64 kiB
- kleine Speicherseite mit 4 kiB
Wieder gilt, dass eine goße Speicherseite 16 gleichlautende Einträge in der Seitentabelle braucht. Durch Nutzung von großen Speicherseiten kann also nicht an Platz für die Seitentabelle gespart werden. In ɒiʜꟼOS werden wir vorerst kleine Speicherseiten nutzen.
Zugriff
Bei einem Speicherzugriff auf die (gültige) logische Speicheradresse adr bei eingeschalteten Paging und zweistufiger Hierarchie geschieht Folgendes:
- Aus dem Register TTBR0 wird die Adresse des Seitenverzeichnisses3 geholt
- Die oberen 12 Bit von adr (also Bit 20 bis Bit 31) dienen als Index im Speicherverzeichnis.
- Die oberen 12 Bits des dort gefundene 32-Bit-Wortes bilden die oberen 12 Bits der Adresse der Seitentabelle, die unteren sind 0.
- Die nächsten 8 Bit von adr (Bits 12 bis Bit 19) sind der Index in dieser Seitentabelle.
- Von dem gefundenen Wort werden die oberen 20 Bit (Bit 12 bis Bit 31) genommen und daran die unteren 12 Bit (Bit 0 bis Bit 11) angehangen. Dieses zusammengesetzt Wort ist die physische Adresse, (Busadresse) auf die tatäsächlich zugegriffen wird.
Die Abbildung zeigt diesen „Tabellenlauf“ (table walk) noch einmal im Zusammenhang.
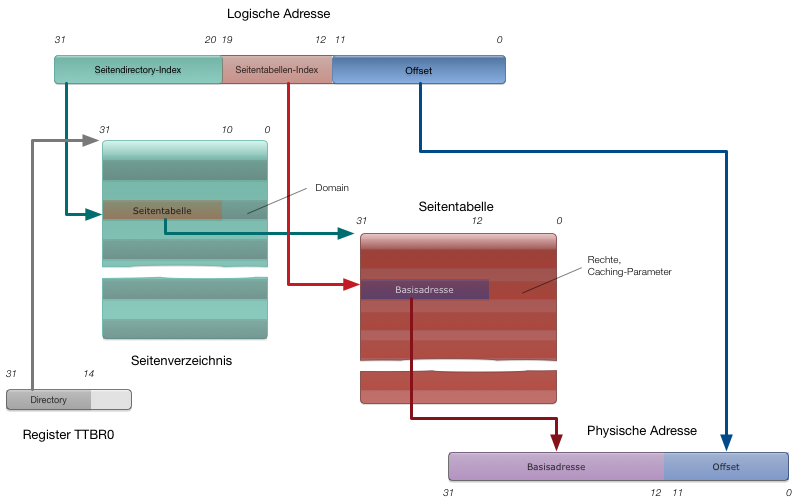
Damit nicht durch die ständigen Speicherzugriffe viel Zeit verloren geht, hat der ARM mehrere Caches, darunter einen TLB .
Rechte und Typen
Die übrig gebliebenen Bits im Seitenverzeichnis und in der Seitentabelle haben auch Aufgaben. Einerseits geben sie an, welches Speicherkonsistenzmodell und damit welche Cachestrategie benutzt werden soll. So ist es z.B. wichtig zu wissen, ob es einen geteilten (shared) Zugriff auf eine Speicherseite gibt.
Andererseits, werden Reche angegeben, also wann und wie auf eine Seite zugegriffen werden darf: * ob lesend+schreibend, nur schreibend, oder gar nicht; * ob in einem privilegierten und/oder im nichtpriviligierten Modus; * ob die Seite ausführbaren Code enthalten darf.
Darüber hinaus gehört jede Seitentabelle einer Domain an. Davon kann es bis zu 16 geben, von denen zu jedem Zeitpunkte eine oder mehrere aktiv sein können. Ist eine Domain nicht aktiv, so führt ein Zugriff auf einen entsprechenden Speicher automatisch zu einem Zugriffsfehler, unabhängig von den Rechten in der Seitentabelle. Auf diese Weise können z.B. bei einem Prozesswechesel Teile des Speichers gesperrt werden, ohne das Seitenverzeichnis zu verändern.
Implementierung
Designentscheidungen
Bevor wir an die Nutzung der Paging-Hardware machen, müssen uns Gedanken über das Speicherlayout machen. Dazu müssen wir einige Aspekte berücksichtigen:
- Da der Zugriff auf das Seitenverzeichnis und die Seitentabellen selbst von der Adressübersetzung betroffen sind, wird es unkomplizierter, wenn die Speicherbereiche in denen sie sich befinden auf sich selbst abgebildert werden.
- Auch für den Kernel-Code ist es einfacher, wenn er in einem auf sich selbst abgebildeten Adressbereich liegt.
- Die (Speicher-)Größe eines Prozesses bestimmt, wieviele Seitentabellen wir für ihn benötigen. Der Einfachheit halber legen wir fest, dass kein Prozess größer als 1 MiB ist, was für alle Fälle reichen sollte. Damit brauchen wir jedem Prozess später nur eine Seitentabelle zuordnen. Zusammen mit der Entscheidung vom letzen Beitrag, die Stacks ans Ende des verfügbaren RAM zu legen, ergibt sich aus Kernel-Sicht folgendes Speicherlayout:
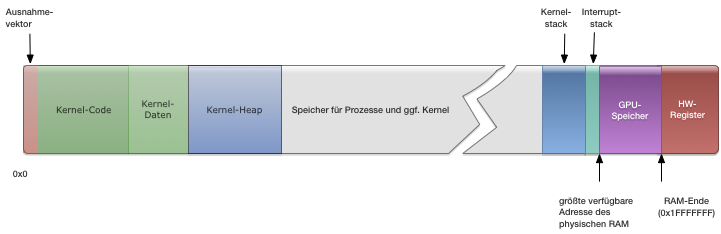
Alle Prozesse sollen logisch den gleichen Adressbereich haben. Wir legen fest, dass der maximal 1 MiB große Adressbereich von 0x02000000 bis 0x020FFFFF geht. Damit ist hinreichen Platz für den Kernel und seine Verwaltungsdaten im unteren Bereich des Speichers. Für einen Prozess sähe der Adressbereich dann ungefähr so aus, wobei die schwarz-gelb schraffierten Gebiete „verboten“ sind, wo ein Speicherzugriff des Prozesses also zu einer Ausnahme führt. Ob der Prozess auf den Adressbereich mit den Geräten zugreifen darf, hängt von seinen Rechten ab; bei Treiberprozessen sollte man einen entsprechenden Zugriff natürlich gestatten.
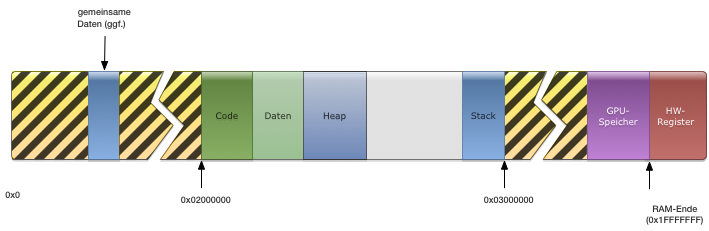
Natürlich liegen die Prozesse nicht wirklich im gleichen (physischen) Speicherbereichen. Vielmehr sind ihre Speicherseiten auf verschiedene Platzhalter (Frames) im Speicher verteilt. Dies Frames, die ein Prozess benutzt, müssen (mit Ausnahme von Speichersharing) in der Tat verschieen sein. Daher besteht eine weitere Aufgabe neben der Verwaltung der Abbildung (mapping) in der Buchhaltung über die Framevergabe. Auch hier steht eine Designentscheidung über die Art und Weise der Frameverwaltung an.
Solange wir noch kein Demand Paging haben, ist eine Buchführung theoretisch redundant: Man kann die belegten Frames ermitteln, indem man das Seitenverzeichnis und alle existierenden Seitentabellen betrachtet und alle Frames in nichtaufgeführten Adressbereichen als leer betrachtet. Aber das ist erstens ein enormer Aufwand, und zweitens nicht sehr zukunftsträchtig, da ɒiʜꟼOS vielleicht tatsächlich mal einen virtuellen Speicher erhalten soll.
Es stellt sich also die Frage, wie die Frameverwaltung organisiert werden soll. Möglich wären – wie beim Heap – Listen mit leeren Frame-Bereichen. Ich habe mich aber für eine andere Lösung entschieden, die etwas unkomplizierter ist: In einem großen Bit-Array werden alle belegten Frames markiert. Bei einem (beim Pi 1B) maximalen RAM vom 512 MiB und einer Seitengröße von 4 kiB gibt es maximal
Frames. Wenn für jedes Frame ein Bit die Belegung anzeigt, hat das Bit-Array eine Größe von
also 16 kiB. Das ist zwar (vermutlich) größer eine Freiframetabelle oder ein ähnliches Konstrukt im Mittel benötigen würde, aber der Worst Case ist bei der Freispeichertabelle wesentlich schlechter.4
Datenstrukturen
Nachdem wir die Designentscheidungen getroffen haben, können die Datenstrukturen festgelegt werden.
Tabelleneinträge
Die einfachsten Datenstrukturen sind die Einträge in den
Seitentabellen bzw. dem Seitenvereichnis: Das in eigentlich nur
32-Bit-Worte, in Rust also u32 (oder usize):
pub type PageDirectoryEntry = u32;
pub type PageTableEntry = u32;
In Rust wird damit nur ein Typenalias geschaffen, für den Typencheck
sind es also immer noch ein u32. Funktionen zum Manipulieren könnten
also nicht unterscheiden, ob sie ein Eintrag in eine Seitentabelle
oder in das Seitenverzeichnis bearbeiten, man hat also keine
Typensicherheit.
Andererseits können die skalaren Grundtypen von Rust nicht einfach so
erweitert werden, wir können also keine zusätzlichen Methoden für
u32 schreiben.
Um trotzdem etwas Abstraktion und Typensicherheit zu erhalten, habe
ich für die Generierung der Tabelleneinträge das
Builder-Muster
ausgewählt, also eine struc, deren Methoden
verkettet werden können und die die gewünschte Datenstruktur erzeugt.
Die Einträge in das Seitenverzeichnis und in eine Seitentabelle haben ähnliche Funktionen. In einer objektorientierten Sprache würde man dies über ein Klassenkonzept oder ein Interface abbilden. In Rust nimmt man zur Beschreibung gemeinsamen Verhaltens einen Trait:
/// `MemoryBuilder` ist eine Builder-Struct für zur Erstellung von Einträgen
/// in das Seitenverzeichnis oder in Seitentabellen
pub struct MemoryBuilder<T>(u32,PhantomData<T>);
impl<DirectoryEntry> MemoryBuilder<DirectoryEntry>{}
impl<TableEntry> MemoryBuilder<TableEntry>{}
/// Einträge in das Seitenverzeichnis (_page directory_) und die Seitentabellen
/// (_page table_) haben ähnliche Funktionalität. Daher haben sie einen Trait als
/// gemeinsames Interface.
pub trait EntryBuilder<T> {
/// Erzeugt einen neuen Eintrag
fn new_entry(kind: T) -> MemoryBuilder<T>;
/// Gibt die Art des Eintrags
fn kind(&self) -> T;
/// Setzt die Basisadresse
fn base_addr(self, a: usize) -> MemoryBuilder<T>;
/// Legt die Art des Speichers (Caching) fest
///
/// * Vorgabe: `StronglyOrdered` (_stikt geordnet_), siehe ARM DDI 6-15
fn mem_type(self, t: MemType) -> MemoryBuilder<T>;
/// Setzt die Zugriffsrechte
///
/// * Vorgabe: Kein Zugriff
fn rights(self, r: MemoryAccessRight) -> MemoryBuilder<T>;
/// Legt fest, zu welcher Domain der Speicherbereich gehört
///
/// * Für Supersections und Seiten wird die Domain ignoriert
/// * Vorgabe: 0
fn domain(self, d: u32) -> MemoryBuilder<T>;
/// Legt Speicherbereich als gemeinsam (_shared_) fest
///
/// * Vorgabe: `false` (nicht gemeinsam)
fn shared(self, s: bool) -> MemoryBuilder<T>;
/// Legt fest, ob ein Speicherbereich global (`false`) oder prozessspezifisch
/// ist. Bei prozessspezifischen Speicherbereichen wird die ASID aus dem
/// ContextID-Register (CP15c13) genutzt.
///
/// * Vorgabe: `false` (global)
/// * Anmerkung: aihPOS nutzt *keine* prozessspezifischen Speicherbereich
fn process_specific(self, ps: bool) -> MemoryBuilder<T>;
/// Legt fest, ob Speicherinhalt als Code ausgeführt werden darf
///
/// * Vorgabe: `false` (ausführbar)
fn no_execute(self, ne: bool) -> MemoryBuilder<T>;
/// Gibt den Eintrag zurück
fn entry(self) -> u32;
}
Für die Implementierung des Traits müssen jetzt nur die Bits nach
Handbuch gesetzt werden. Ich habe für die Bitmanipulation wieder
die Bitfield-Crate genutzt. Folgender Codeausschnitt zeigt
exemplarische die Implementation der Methode, die für einen
Seitentabelleneitrag festlegt, ob die entsprechende Speicherseite
ausführbaren Code enthalten darf:
fn no_execute(mut self, ne: bool) -> MemoryBuilder<TableEntry> {
match self.kind() {
TableEntry::LargePage
=> { self.0.set_bit(15,ne); },
TableEntry::SmallPage
=> { self.0.set_bit(0,ne); },
_ => {}
}
self
}
Wenn dann ein Mapping – also eine Abbildung zwischen logischen und physischen Adressen – festgelegt wird, werden einfach die Methoden der Builder-struct verkettet, bis der gewünschte Eintrag entstanden ist, wie folgendes Beispiel aus dem Initalisierungscode zeigt:
kpage_table[frm.rel()] = MemoryBuilder::<TableEntry>::new_entry(TableEntry::SmallPage)
.base_addr(frm.start())
.rights(MemoryAccessRight::SysRwUsrNone)
.mem_type(MemType::NormalWT)
.domain(0)
.entry();
Tabellen
Die Tabellen (Seitentabellen und Seitenverzeichnis) sind im
Endergebnis einfache Arrays. Um aber auch hier Typensicherheit zu
erhalten und das richtige Alignment zu erzwingen, werden diese Arrays
jeweils Elemente eines Verbundstyps (struct).
Damit man trotzdem wie auf ein Array zugreifen kann, also der
[ ]-Operator funktioniert, muss der Index- und der
IndexMut-Trait implementiert werden:
use core::ops::{Index, IndexMut};
use super::builder::{PageTableEntry,TableEntry,MemoryBuilder,EntryBuilder};
use super::Address;
#[repr(C)]
#[repr(align(1024))]
pub struct PageTable {
table: [PageTableEntry;256]
}
impl PageTable {
/// Erzeugt eine neue Tabelle
pub const fn new() -> PageTable {
PageTable {
table: [0;256]
}
}
/// Füllt die Tabelle mit Seitenfehlern
pub fn invalidate(&mut self) {
for ndx in 0..256 {
self.table[ndx] = MemoryBuilder::new_entry(TableEntry::Fault).entry();
}
}
/// Addresse der Tabelle
pub fn addr(&self) -> Address {
self as *const _ as usize
}
}
impl Index<usize> for PageTable {
type Output = PageTableEntry;
fn index(&self, index: usize) -> &PageTableEntry {
&self.table[index]
}
}
impl IndexMut<usize> for PageTable {
fn index_mut(&mut self, index: usize) -> &mut PageTableEntry {
&mut self.table[index]
}
}
Frames
Ein Frame ist ein Bereich von Adressen, der genau eine Speicherseite
groß ist. Wir könnten also Range<usize> als Typ nutzen. Allerdings
werden wir auch mit anderen Adressbereichen umgehen, und so hätten wir
wieder keine Typensicherheit. Da aber Frames Gegensatz zu
Tabelleneinträgen evtl. nicht nur konstruiert und zugewiesen werden
(wir werden später einen Frame-Iterator brauchen), nehmen wir diesmal
ein anderes Muster, um Range zu erweitern: Wir schaffen einen neuen
Typ:
pub type Address = usize;
pub type AddressRange = Range<Address>;
#[derive(Debug)]
pub struct Frame(AddressRange);
Dafür implementieren wir eine Handvoll von Methoden:
impl Frame {
/// Frame aus absoluter Framenummer
pub fn from_nr(nr: usize) -> Self {
Frame (
AddressRange {
start: nr * PAGE_SIZE,
end: (nr * PAGE_SIZE) + (PAGE_SIZE - 1),
})
}
/// Frame mit einer gegebenen Startadresse
pub fn from_start(start: Address) -> Self {
assert_eq!(start & (PAGE_SIZE - 1), 0);
Frame (AddressRange {
start: start,
end: start + (PAGE_SIZE - 1),
})
}
/// Frame, der gegebene Adresse enthält
pub fn from_addr(addr: Address) -> Self {
let start = addr & !(PAGE_SIZE - 1);
Frame::from_start(start)
}
/// Start des Frames
pub fn start(&self) -> Address {
self.0.start
}
/// Ende (inklusiv) des Frames
pub fn end(&self) -> Address {
self.0.end
}
/// Absolute Nummer des Frames
pub fn abs(&self) -> usize {
self.0.start / PAGE_SIZE
}
/// Nummer der Section, zu dem der Frame gehört
pub fn section(&self) -> usize {
self.0.start / SECTION_SIZE
}
/// Nummer des Frames innerhalb der Section / Seitentabelle
pub fn rel(&self) -> usize {
(self.0.start % SECTION_SIZE) / PAGE_SIZE
}
/// Iterator über Frames eines Adressbereiches
pub fn iter(r: AddressRange) -> FrameIterator {
FrameIterator {
range: AddressRange{ start: r.start,
end: r.end - 1},
current: Some(Frame::from_addr(r.start))
}
}
}
Die iter()-Methode gibt einen Iterator zurück, der natürlich auch
implementiert werden muss. Die Idee dabei ist, dass für einen
beliebigen gegebenen Adressbereich alle darin (ggf. teilweise)
enthaltenen Frames iteriert wird.
pub struct FrameIterator {
range: AddressRange,
current: Option<Frame>,
}
impl Iterator for FrameIterator {
type Item = Frame;
fn next(&mut self) -> Option<Self::Item> {
if self.current.is_some() {
let tmp = Frame::from_start(self.current.as_ref().unwrap().start());
self.current =
if tmp.end() >= self.range.end {
None
} else {
Some(Frame::from_start(tmp.start() + PAGE_SIZE))
};
Some(tmp)
} else {
None
}
}
}
Frame-Manager
Der Frame-Manager verwaltet – wie oben diskutiert – ein Bitarray. Er enthält zusätzlich eine Indexvariable, die auf den ersten freien Frame zeigt. Da Reservierung nicht zusammenhängend sein müssen und es eine feste Stückelung gibt, ist Verschnitt kein Problem.
const BITVECTOR_SIZE: usize = (MEM_SIZE / (PAGE_SIZE * mem::size_of::<u64>() * 8)) as usize;
/// FrameManager verwaltet die Allozierung von Frames.
/// Jedes Bit in `bits` steht für einen Frame.
pub struct FrameManager {
bits: [u64; BITVECTOR_SIZE],
first_free: usize,
}
Die Suche nach einem freien Frame ist linear und hat somit eine Komplexität von \(\mathcal{O}(n)\).
/// Sucht den nächsten freien Frame und gibt die Nummer zurück
fn find_next_free(&self, start: Address) -> usize {
let mut ndx = start;
while (self.get_bit(ndx)) && (ndx < self.bit_length()) {
ndx += 1;
}
ndx
}
Ansonsten ist der Frame-Manager ziemlich unkomplizert
implementiert. Einzig bemerkenswert ist vielleicht, dass wir bei ihm das
Singleton-Muster
implementieren (schließlich wollen wir nicht Gefahr laufen, mehrere
Instanzen einer so großen Datenstruktur im Speicher und wohlmöglich
auf dem Stack zu haben.)5 Daher ist der Konstruktor und die
statische Variable, die wieder NoConcurrency nutzt, privat:
/// Erzeugt einen neuen Framemanager
///
/// # Anmerkung
/// Der Framemanager ist ein Singleton, daher ist `new()` nicht öffentlich
/// Zugriff erhält man über die assoziierte Methode `get()`.
const fn new() -> FrameManager {
FrameManager {
bits: [0u64; BITVECTOR_SIZE],
first_free: 0,
}
}
// ...
/// Das Singleton für den Framemanager, nicht geschützt vor nebenläufigen Zugriff
static FRAME_MANAGER: NoConcurrency<FrameManager> = NoConcurrency::new(FrameManager::new());
Zugriff erhält man über eine assoziierte Methode der struct
FrameManager:
/// Gibt eine Referenz auf Framemanager-Singleton zurück
pub fn get() -> &'static mut FrameManager {
FRAME_MANAGER.get()
}
Und da wir gerade dabei sind, machen wir auch das Seitenverzeichnis auf die gleiche Weise zum Singleton.
In die Niederungen
Bisher konnten wir mit den Abstaktionen, die uns Rust zur Verfügung
gestellt hat, gut auskommen. Das ist nun vorbei: Die eigentliche
Aktivierung des Pagings verlangt Assembler-Code. Glücklicherweise kann
dieser ja gut in Rust eingebettet werden mit Hilfe des
(selbstverständlich unsicheren) Macros asm!().
Die Aktivierung erfolgt durch setzen eines bstimmten Bits in einem bestimmten Register des CP15-Koprozessors. Dieser Koprozessor ist nur konzeptionell ein eigener Prozessor und auf einem Chip zusammen mit dem „Rest-ARM“. Das Technischen Manual des ARM1176JZF-S schreibt folgende Schritte bei der MMU-Aktivierung vor, (vgl. Abschnitt 6.4.1, S. 6-9):
- Programmiere alle relevanten CP15-Registers.
- Programmere Seitenverzeichnis und Seitentabellen wie benötigt.
- Schalte den Instruktionscache ab und mache seine Einträge ungültig. Er kann nach dem Start der MMU wieder aktiviert werden.
- Setze das Bit 0 im CP15-Steuerregister
Das setzen wir so um (und legen gleichzeitig noch fest, dass wir das ARMv6-MMU-Protokoll ohne Subpages nutzen wollen:
pub unsafe fn start(){
let mut reg: u32;
Cache::clean();
Cache::disable_instruction();
Cache::invalidate_instruction();
Cache::disable_data();
Tlb::flush();
asm!("mrc p15, 0, $0, c1, c0, 0":"=r"(reg));
reg.set_bit(23,true); // Subpages aus, ARMv6-Erweiterungen an
reg.set_bit(0,true); // MMU an
Cpu::data_synchronization_barrier();
asm!("mcr p15, 0, $0, c1, c0, 0"::"r"(reg)::"volatile");
Cpu::prefetch_flush();
Cpu::data_synchronization_barrier();
Cache::enable_instruction();
Cache::enable_data();
}
Die anderen Cpu- und Cache-Methoden sind ebenfalls Methoden, wo
die eigentliche Arbeit durch Assemblercode verrichtet wird. Da es hier
auf jedes einzelne Bit ankommt, gilt die Devise: „Genau das Handbuch
lesen und exakt nachvollziehen“. Wie dies im einzelnen aussieht, kann
wieder auf
GitHub
betrachtet werden.
Schlussbemerkung
Die Implementation einer MMU-Steuerung ist eine heikle Sache. Ich war froh, als der Code zum ersten Mal ohne einen „Abort“ aus der MMU-Aktivierungsmethode zurückgekehrt ist.
Natürlich kann ein solcher Abort auch abgefangen und eine schöne Meldung ausgegenen werden. Und natürlich habe ich das auch gemacht, aber davon berichte ich in einer der nächsten Folgen dieses Blogs.
-
Umgangssprachlich wird mit Paging fast immer Demand Paging, also die virtuelle Speicherverwaltung mit Auslagerung auf die Festplatte gemeint. Jedoch lässt sich eine seitenbasierte gestreute Adressierung auch sinnvoll ohne Auslagerung einsetzen. ↩
-
Das hier beschriebene Paging-Schema entspricht ARMv6. Der Prozessor ist in einigen Aspekten der Speicherverwaltung rückwärtskompatibel zu ARMv5 (z.B. Supbages). Dies werden wir nicht benutzen. ↩
-
Es gibt auch ein Schema mit zwei Seitenverzeichnissen, das hier aber nicht betrachtet wird. ↩
-
Im pathologischen Fall würde jeder zweite Frame frei sein. Eine Speicherstruktur, die die Adressen (4 Byte) und die Länge (4 Byte) der Leer-Frame-Bereiche speichert, bräuchte dann mindestens \(\frac{131072}{2}\cdot(4 + 4) = 524288\) Byte, also ein halbes MiB! ↩
-
Genau genommen haben wir das Muster bereits beim Framebuffer benutzt. ↩
Kommentare