ɒiʜꟼOS soll ein dynamisches Betriebssystem werden, also eines, bei denen die Anzahl der Prozesse sich zur Laufzeit ändern kann. Unser Mikrokernel hat eine klassische Architektur, die aus vier Schichten besteht:
- Schicht 4: der Kernoperation, der wie Prozessverwaltung, Prozessinteraktion oder Prozessspeichermanagement
- Schicht 3: Prozesswechseloperationen; hier wird die Abstraktion Prozess gewährleistet
- Schicht 2: Datenstrukturen
- Schicht 1: Kernel-Speicherverwaltung
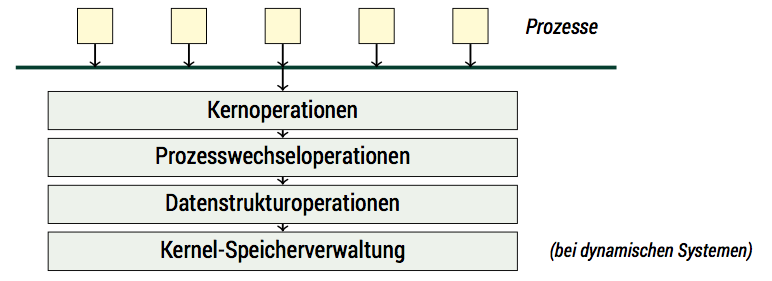
Damit wäre eine der ersten Aufgaben, sich um den Speicher kümmern.
Speicher in verschiedenen Geschmacksrichtungen
Die Speicherverwaltung in Betriebssystemen hat verschiedene Aspekte:
- Prozesse und der Kernel brauchen eine Buchführung über bei Operationen wie
mallocodernewallozierten1 Speicher. Das Modell des Speichers ist hier ein linearer Adressraum. Die Herausforderung besteht, möglichst wenig Overhead und eine möglichst kleinen Verschnitt zu produzieren. - Der insgesamt zur Verfügung stehende Speicher muss zwischen den einzelnen Prozessen verteilt werden. Hierbei geht es nicht nur um die Reservierung von Speicherbereichen, sondern um die Abbildung der Prozesssicht (logische Adressen) auf die Prozessorsicht (physische Adresse). Verwaltungseinheiten sind hier in der Regel physische Speicherseiten (Pages) oder Segmente.
- Die Prozesse und der Kernel müssen vor ungewollten Speichereingriffen anderer Prozessen geschützt werden.
- Häufig sollen die vorhandenen Speicherreserven durch Nutzung einer Speicherhierachie virtuell vergrößert werden.
ɒiʜꟼOS soll (zunächst) die ersten drei Aspekte unterstützen; eine virtuelle2 Speicherverwaltung kann erst in Angriff genommen werden, wenn es Treiber für Speichermedien wie die SD-Karte oder externe USB-Laufwerke gibt.
Dabei muss erst einmal der Kernel selbst seinen Speicher verwalten. Dabei stellt sich natürlich die Frage: wie hat er das in unseren bisherigen Programmen gemacht? Da haben wir doch auch schon Speicher (in Form von Variablen) benutzt. Das waren einmal statische (aus Programmsicht: globale) Variablen, wie der Framebuffer. Diese haben eine Lebenzeit, die die Lebenzeit des ganzen Programmes umfasst. Variablen mit beschränkter Lebenzeit muss zur Laufzeit Speicher alloziert werden. Dies wird auf zwei verschiedene Arten und an zwei verschiedenen Orten realisert3 :
- Auf dem Stack. Dort werden nicht nur Rücksprungadressen gespeichert, sondern auch lokale Variablen einer Funktion. Beim Verlassen der Funktion werden diese automatisch aufgeräumt.
- Auf dem Heap. Dort werden Variablen angelegt, die die Laufzeit einer Funktion überdauern. Diese müssen dann entweder manuell weggeräumt werden, oder es existiert eine Speicherberäumung (garbage collection)
Stack
Prozessor-Modi
Bisher haben wir ausschließlich den Stack benutzt, und zwar den Stack im SVC-Mode. Im Gegensatz zu beispielsweise dem x86-Prozessoren kennt ARM nämlich mehrere Stacks. Diese sind an Prozessor-Modi gebunden. Im einzelnen es beim ARM1176JZF-S folgende Modi:
- Supervisor-Mode (SVC): Mode, in dem die CPU startet und mit dem wir es bisher zu tun hatten. Er ist privilegiert, hat also die volle Kontrolle über die CPU.
- User-Mode: unprivilegierter Mode, der für normale Programme genutzt wird.
- System-Mode: privilegierter Mode mit der gleichen „Sicht“ wie der User-Mode.
- Interrupt-Mode (IRQ): Mode in dem zur Behandlung eines Interrupts gewechselt wird.
- Fast-Interrupt-Mode (FIQ): Mode für die besonders schnelle Behandlung eines Interrupts.
- Memory-Abort (ABT): Mode, in dem zur Behandlung eines Traps (also internen Interrupts) gewechselt wird, der durch einen ungültigen Speicherzugriff ausgelöst wird. Ursache können z.B. fehlende Zugriffsrechte sein.
- Undefined-Instruction-Exception (UND): Ein weiterer Trap-Behandlungsmode, in den gewechselt wird, wenn ein unbekannter Op-Code gelesen wird. Damit kann ein erweiterter Befehlssatz emuliert werden.
- Secure-Monitor-Mode (MON): Der ARM1176JZF-S hat eine Erweiterung (TrustZone), bei der zwischen einer vertrauenswürdigen und einer unsicheren „Welt“ unterschieden wird. Der Secure-Monitor-Mode dient der Interaktion dieser Welten.
Da wir die TrustZone-Erweiterung nicht nutzen wollen, ist der letzte Mode für uns nicht interessant. Um die andern müssen wir uns kümmern. Dabei hat jeder Mode seinen eigenen Stackpointer und sein eigenes Link-Register. Eine Ausnahme ist der System-Mode, der sich alle Register mit dem User-Mode teilt. Wir werden aber nicht für jeden Mode einen eigenen Stack anlegen: Da die meisten Modi entweder ihren Stack aufräumen, oder nicht zurückkehren, können sie sich (erst mal) einen Stack teilen. Dieser Stack soll im weiteren Interrupt-Stack heißen.
Ja, wo liegen sie nur?
Wo sollen nun die Stacks liegen? Da Stacks traditionell4 nach „untern“ wachsen, legen wir sie möglichst „hoch“. Da der Interrupt-Stack vorhersagbarer als der SVC-Stack ist, setzen wir ihn ganz an das Ende des verfügbaren Speichers und den SVC-Stack ein Stück weit darunter. Allerdings kann das Ende des Speichers variieren, da es zur Bootzeit die Aufteilung zwischen ARM und GPU geändert werden kann. Glücklicherweise haben wir in der vorletzten Folge das Mailbox-System implementiert, mit dem wir ja das Ende des Speichers herausfinden können.
Allerdings geschieht dies zur Laufzeit – d.h., wir brauchen bereits einen Stack. Wir müssen also mit einem provisorischen Stack beginnen um später zu wechseln. Damit sieht unsere Einsprungssequenz in den Kernel jetzt so aus:
#[no_mangle] // Name wird für den Export nicht verändert
#[naked] // Kein Prolog, da dieser den Stack nutzen würde, den wir noch nicht gesetzt haben
#[allow(unreachable_code)]
pub extern fn kernel_start() {
// Zum Start existiert noch kein Stack. Daher setzen wir einen temporären Stack, der nach dem Textsegment liegt.
// Das Symbol ist in "layout.ld" definiert.
Cpu::set_stack(unsafe {&__kernel_stack} as *const u32 as u32);
// Nun kann die Größe des Speichers und damit die Adresse für den "echten" Stacks bestimmt werden
Cpu::set_stack(determine_svc_stack());
kernel_init();
unreachable!();
}
#[inline(never)] // Verbietet dem Optimizer, kernel_init() und darin aufgerufene Funktionen mit kernel_start()
// zu verschmelzen. Dies würde wegen #[naked]/keinen Stack schief gehen
#[allow(unreachable_code)]
fn kernel_init() -> ! {
report();
init_mem();
test();
loop {}
unreachable!();
}
fn determine_irq_stack() -> u32 {
let addr = (report_memory(MemReport::ArmSize) - 3) & 0xFFFFFFFC;
addr
}
#[inline(never)]
fn determine_svc_stack() -> u32 {
let addr = ((report_memory(MemReport::ArmSize) - 3) & 0xFFFFFFFC) - IRQ_STACK_SIZE;
addr
}
fn init_mem() {
init_stacks();
init_heap();
init_paging();
}
fn init_stacks() {
// Stack für die anderen Ausnahme-Modi. Irq, Fiq, Abort und Undef teilen sich einen Stack, der System-Mode nutzt
// den User-Mode-Stack und muss nicht gesetzt werden.
let adr = determine_irq_stack();
Cpu::set_mode(ProcessorMode::Irq);
Cpu::set_stack(adr);
Cpu::set_mode(ProcessorMode::Fiq);
Cpu::set_stack(adr);
Cpu::set_mode(ProcessorMode::Abort);
Cpu::set_stack(adr);
Cpu::set_mode(ProcessorMode::Undef);
Cpu::set_stack(adr);
// ...und zurück in den Svc-Mode
Cpu::set_mode(ProcessorMode::Svc);
}
fn init_heap() {
unimplemented!();
}
fn init_paging() {
unimplemented!();
}
HAL
Cpu::set_mode() und Cpu::set_stack() sind natürlich keine Funktionen, die Rust bekannt sind. Der Übersichtlichkeit halber habe ich allen Assembler-Code in ein eigenes
Modul gepackt, das „HAL“ heißt. HAL steht klassischerweise für „Hardware Abstraction Layer“. Allerdings ist die Abstraktion in ɒiʜꟼOS sehr dünn, ein Port über die
ARM-Architektur hinaus bedürfte etwas mehr Aufwand. Der Code für Cpu::set_mode() und Cpu::set_stack() sieht derzeit so aus:
// Siehe ARM Architectur Reference Manual A2-3
pub enum ProcessorMode {
User = 0x10,
Fiq = 0x11,
Irq = 0x12,
Svc = 0x13,
Abort = 0x17,
Undef = 0x1B,
System = 0x1F,
}
pub struct Cpu {}
impl Cpu {
#[inline(always)]
pub fn set_mode(mode: ProcessorMode) {
unsafe{
match mode {
ProcessorMode::User => asm!("cps 0x10"),
ProcessorMode::Fiq => asm!("cps 0x11"),
ProcessorMode::Irq => asm!("cps 0x12"),
ProcessorMode::Svc => asm!("cps 0x13"),
ProcessorMode::Abort => asm!("cps 0x17"),
ProcessorMode::Undef => asm!("cps 0x1B"),
ProcessorMode::System => asm!("cps 0x1F"),
};
}
}
#[inline(always)]
pub fn set_stack(adr: u32) {
unsafe{
asm!("mov sp, $0"::"r"(adr)::"volatile");
}
}
}
Heap
Nachdem die Stacks initialisiert sind, kümmern wir und um den Kernel-Heap. Es stellt sich die Frage, wie groß der Heap sein soll. Das ist schlecht beantwortbar, da wir viele Aspekte von ɒiʜꟼOS noch nicht kennen. Natürlich können wir versuchen, ihn auf den worst case auszulegen, aber das würde für den Großteil der Fälle eine Verschwendung bedeuten. Am besten wäre es, wenn der Heap erst mal eher klein ist und später wächst. Allerdings ist das problematisch: der Heap ist ein zusammenhängender Adressraum. Wenn in der Zwischenzeit eine bestimmte Adresse anderweitig vergeben ist (sagen wir mal an einen Prozess), kann der Heap nicht weiter wachsen.5 An dieser Stelle kommt zum ersten Mal die gestreute Adressierung ins Spiel, die dafür sorgen, dass physisch unzusammenhängende Adressbereiche einen logisch zusammenhängenden Adressraum bilden. Für die gestreute Adressierung ist die MMU zuständig – wir betrachten das später. Erst einmal ist es nur wichtig zu vermerken, dass es einen Zusammenhang gib, den wir berücksichtigen sollten.
Rust Allocator
Die Module, die den Heap verwalten, heißen in Rust „Allokatoren“. Rust wird mit zwei verschiedenen Allokatoren ausgeliefert, malloc(wohlbekannt aus der
C-Standardbibliothek) und jemalloc. Beide nutzen jedoch Betriebssystemrufe, die unter ɒiʜꟼOS erstens nocht gar nicht existieren, und zweitens im Kernel schlecht genutzt
werden könnten – also fallen beide aus.
Glücklicherweise kennt Rust das Konzept von maßgeschneiderten Allokatoren (custom allocators). Für einen solchen Allokator gibt es einige Spielregeln:
Achtung
Das Konzept der Allokatoren hat sich mit der neuen Allokator-API grundlegend gewandelt.
Die folgenden Betrachtungen lasse ich wiederum aus „historischen“
Gründen stehen.
- Er muss in einer eigenen Bibliothek stehen, die mit
#![allocator]dekoriert ist. - Die Bibliothek muss folgende fünf Funktionen zur Verfügung stellen:
pub extern fn __rust_allocate(size: usize, align: usize) -> *mut u8pub extern fn __rust_deallocate(ptr: *mut u8, old_size: usize, align: usize)pub extern fn __rust_reallocate(ptr: *mut u8, old_size: usize, size: usize, align: usize) -> *mut u8pub extern fn __rust_reallocate_inplace(_ptr: *mut u8, old_size: usize, size: usize, align: usize) -> usizepub extern fn __rust_usable_size(size: usize, _align: usize) -> usize- Die Bibliothek darf kein anderes Crate nutzen, das selbst einen Allokator benötigt.
Da unser Allokator (später) mit der MMU-Steuerung zusammenarbeiten muss, ist die Forderung nach einer eigenen Bibliothek eher hinderlich. Wir behelfen uns mit einem Trick, um Callbacks und ähnliches zu umgehen: Alle Funktionen rufen äquivalente Funktionen, die in der Bibliothek unaufgelöst bleiben und durch den Kernel direkt zu Verfügung gestellt werden. Dazu legen wir ein Verzeichnis libs an, und darin eine Untercrate kalloc:
$mkdir libs
$cd libs
$cargo new kalloc
Created library kalloc project
$ls kalloc
Cargo.toml srcDie Datei lib.rs in src ist daher recht schlicht:
#![feature(allocator)]
#![allocator]
#![no_std]
///! Rust verlangt für einen Allocator eine eigene Bibliothek, die mit #![allocator] dekoriert ist.
///! Um bei Erschöpfung des Heaps eine Seitenneuzuweisung ohne Systemruf und Callback auslösen zu können,
///! ist die eigentliche Funktionalität in mem implementiert.
extern "Rust" {
fn aihpos_allocate(size: usize, align: usize) -> *mut u8;
fn aihpos_deallocate(ptr: *mut u8, size: usize, align: usize);
fn aihpos_usable_size(size: usize, align: usize) -> usize;
fn aihpos_reallocate_inplace(ptr: *mut u8, size: usize,
new_size: usize, align: usize) -> usize;
fn aihpos_reallocate(ptr: *mut u8, size: usize, new_size: usize,
align: usize) -> *mut u8;
}
// Die offizielle Schnittstelle zu Rust sieht für einen Allocator so aus,
// vgl. Rust - The Unstable Book: https://doc.rust-lang.org/nightly/unstable-book/language-features/allocator.html
#[no_mangle]
pub extern fn __rust_allocate(size: usize, align: usize) -> *mut u8 {
unsafe{
aihpos_allocate(size, align)
}
}
#[no_mangle]
pub extern fn __rust_deallocate(ptr: *mut u8, size: usize, align: usize) {
unsafe{
aihpos_deallocate(ptr, size, align)
}
}
#[no_mangle]
pub extern fn __rust_usable_size(size: usize, align: usize) -> usize {
unsafe{
aihpos_usable_size(size, align)
}
}
#[no_mangle]
pub extern fn __rust_reallocate_inplace(ptr: *mut u8, size: usize,
new_size: usize, align: usize) -> usize
{
unsafe{
aihpos_reallocate_inplace(ptr, size, new_size, align)
}
}
#[no_mangle]
pub extern fn __rust_reallocate(ptr: *mut u8, size: usize, new_size: usize,
align: usize) -> *mut u8 {
unsafe{
aihpos_reallocate(ptr, size, new_size, align)
}
}
Dies gibt uns die Chance, das eigentliche Heap-Management direkt im Kernel zu implementieren. Dazu muss im Haupt-Cargo-File noch die entsprechende Abhängigkeit deklariert werden:
[dependencies]
bit_field = "0.7.0"
compiler_builtins = { git = "https://github.com/rust-lang-nursery/compiler-builtins", features = ["mem"] }
compiler_error = "0.1.1"
kalloc = { version = "0.1.0", path = "libs/kalloc" }
Algorithmus
Zur Verwaltung von gibt es eine ganze Reihe von Ansätzen. Prinzipiell gibt es mehrere Designziele:
- Möglichst hohe Geschwindigkeit beim Allozieren, Freigabe und Wiedereingliedern6
- Geringer Verschnitt
- Geringer Speicheroverhead
Da wir nun leicht fremde Bibliotheken einbinden können, schauen wir uns mal auf crates.io um, ob sich nicht geeignete Algorithmen finden lassen. Und in der Tat gibt es eine nahezu unüberschaubare Anzahl von Allokatoren. Jedoch sind die wenigsten davon bare-metal-geeignet, sondern dienen als Allokatoren für spezifische (Betriebs-)Systeme oder Einsatzfälle.
Zu den bare-metal-tauglichen Allokatoren zählen: - Buddy-Allokator (siehe Vorlesung) - Linked-List-Allokator: Freispeicher wird durch eine verlinkte Liste verwaltet - Slab-Allokator: Vorhalten von vorgefertigten Speicherstückchen
Obwohl er nicht das beste Laufzeitverhalten hat, werden ich vorläufig den Linked-List-Allokator verwenden. Dafür glänzt es mit einem Speicheroverhead und (internen) Verschnitt von (nahezu) null. Vielleicht werden ich ihn später ein zu einem Boundary-Tag-Allokator überarbeiten, der ein besseres Zeitverhalten bei der Eingliederung hat (mit einem leicht erhöhten Overhead).
Meine heap.rs sieht jetzt so aus:
extern crate linked_list_allocator;
use core::{ptr, cmp};
use self::linked_list_allocator::Heap;
use sync::no_concurrency::NoConcurrency;
static HEAP: NoConcurrency<Option<Heap>> = NoConcurrency::new(None);
pub extern fn init_heap(start: usize, size: usize) {
unsafe{HEAP.set(Some(Heap::new(start,size)))};
}
#[no_mangle]
pub extern fn aihpos_allocate(size: usize, align: usize) -> *mut u8 {
let hpo = HEAP.get();
match *hpo {
Some(ref mut heap) => {
let ret = heap.allocate_first_fit(size, align);
match ret {
Some(ptr) => ptr,
None => {
// ToDo: Reservierung zusätzlicher Seiten durch die logische Addressverwaltung => später
panic!("Out of memory");
}
}
},
None => {
panic!("Uninitialized heap");
}
}
}
#[no_mangle]
pub extern fn aihpos_deallocate(ptr: *mut u8, size: usize, align: usize) {
let hpo = HEAP.get();
match *hpo {
Some(ref mut heap) => {
unsafe { heap.deallocate(ptr, size, align) };
},
None => {
panic!("Uninitialized heap");
}
}
}
#[no_mangle]
#[allow(unused_variables)]
pub extern fn aihpos_usable_size(size: usize, align: usize) -> usize {
size
}
#[no_mangle]
#[allow(unused_variables)]
pub extern fn aihpos_reallocate_inplace(ptr: *mut u8, size: usize,
new_size: usize, align: usize) -> usize {
size
}
#[no_mangle]
pub extern fn aihpos_reallocate(ptr: *mut u8, size: usize, new_size: usize,
align: usize) -> *mut u8 {
let new_ptr = aihpos_allocate(new_size, align);
unsafe { ptr::copy(ptr, new_ptr, cmp::min(size, new_size)) };
aihpos_deallocate(ptr, size, align);
new_ptr
}
Im Quelltext sind die Stellen im Kommentar markiert, an denen später mit der Seitenverwaltung zusammengearbeitet werden soll. Die Initialisierung erfolgt von main.rs aus. Dafür wird dort noch die initiale Heap-Größe festgelegt…
pub const INIT_HEAP_SIZE: usize = 25 * 4096; // 25 Seiten = 100 kB
…und die Heap-Initialisierung gerufen
fn init_heap() {
mem::init_heap(__bss_start as usize, INIT_HEAP_SIZE);
}
Das Symbol __bss_start kommt aus layout.ld, die entsprechend überarbeitet werden muss. Es solle den Beginn des freien, also zu verwaltenden Speichers markieren.
Dann kann in main.rs das entsprechende externe Symbol deklarieren.
Hierbei nutze ich einen Trick: Da die externen Symbole ungetypt sind, erkläre ich es einfach zu einer Funktion:
extern "C" {
fn __bss_start();
}
Damit kann die Funktionsadresse einfach in einen usize gewandelt werden. Wenn man statt dessen als Deklaration z.B.
extern {
static __bss_start: u32;
nehmen würde, wäre der Umwandlung komplexer und außerdem unsicher:
mem::init_heap(&unsafe{__bss_start} as *const u32 as usize, INIT_HEAP_SIZE);
Allerdings kann die Deklaration so Verwirrung stiften; ich sollte vermutlich ein Makro als syntaktischen Zucker schreiben, dass einen aussagekräftigen Namen hat. Schließlich ist gute Lesbarkeit ein Ziel in ɒiʜꟼOS.
Vektoren, Hashes & Co
Und was hat man nun davon? Viel! Jetzt können einige Standardtypen von Rust genutzt werden, die uns bisher verschlossen waren. Dazu gehören:
- Vektoren (Typ:
Vec<T>) - Queues (Typ:
VecDeque<T>) - Strings ohne fixe Länge (Typ:
String) - Mengen (Typ:
BTreeSet<T>)
und noch vieles mehr. Außerdem können jetzt explizit Daten auf den Heap gespeichert werden, was die (unsichere!) Nutzung von static mut weitgehend obsolet macht.
Um dies alles Nutzen zu können, müssen die beiden Crates alloc und collections7 eingebunden werden.
Allerdings ergibt die Einbindung der Crates mit
extern crate alloc;
extern crate collctions;
einen Compilerfehler:
$cargo kernel –target=arm-none-eabihf
Compiling aihPOS v0.0.2 (file:///Users/mwerner/Development/aihPOS/aih_pos/kernel)
error[E0463]: can‘t find crate for alloc
–> src/main.rs:29:1
|
29 | extern crate alloc;
| ^^^^^^^^^^^^^^^^^^^ can‘t find crate
error: aborting due to previous error(s)
error: Could not compile aihPOS.Ursache ist diesmal xargo. Es übersetzt standardmäßig nur core, aber nicht die anderen Bibliotheken. Um dies zur erreichen, muss man eine weitere Konfigurationsdatei
im Wurzelverzeichnis anlegen: Xargo.toml. Dort können zusätzliche Crates der Standard-Bibliothek angegeben werden:
[dependencies]
alloc = {}
collections = {}
Nun funktioniert die Übersetzung reibungslos. Auch Codezeilen wie
use collections::vec::Vec;
let v = vec![1,2,3];
sind jetzt möglich.
Damit haben wir eine vorläufige Lösung für die unterste Kernel-Schicht. Nebenbei werden uns auch viele Datenstrukturen geschenkt, die wir sonst in Schicht 2 implementieren müssten. Allerdings ist das Thema Speicher noch nicht erledigt: Speicher ist auch Betriebsmittel für die Prozesse. Hier kommt die logische Speicherverwaltung ins Spiel, siehe die Diskussion oben. Aber das ist Thema des nächsten Beitrags in der ɒiʜꟼOS-Reihe.
-
Achtung: Mitunter (auch in der ARM-Dokumentation) wird schon von „virtueller Speicherverwaltung“ gesprochen, wenn eine streuende Adressabbildung erfolgt. Hier wird „Virtualisierung“ aber im engeren Sinne verstanden, also so, dass mehr Ressourcen simuliert werden als vorhanden sind. Damit ist die Unterstützung der streuenden Adressierung nur ein Teil der Speichervirtualisierung. ↩
-
Es gibt noch mehr Möglichkeiten; hier werden nur die beiden wichtigsten Arten besprochen. ↩
-
Für den ARM ist das lediglich eine Konvention, die Hardware unterstützt auch Stacks, die nach oben wachsen. ↩
-
Es gibt zwar auch das Konzept eines fragmentierten Heaps, aber das ist relativ kompliziert zu implementieren und ɒiʜꟼOS soll ja einfach werden. :-) ↩
-
Freigabe und Wiedereingliedern wird häufig zusammen erledigt. ↩
-
Es gibt Bestrebungen, diese beiden Crates zusammenzulegen, derzeit sind sie aber noch getrennt. ↩
Kommentare